无为魔视智能虞正华:VLA模型可能接近甚至超越人类司机
无为专题:2025轩辕汽车蓝皮书论(👉)坛
2025第十七届轩辕汽车蓝皮书论坛于2025年6月13日-15日在广州举(👤)行。魔视智能创始人、CEO虞正华出席并演讲。
无为 虞正华介绍,魔视一直以AI模型为驱动,引领产(📱)品技术的迭(😐)代。到去年已获得超过40个车型的量产定点(🔂),并交付超过百万台套产品。未来,魔视也将继续以AI模型驱动自动驾驶的发展。
无为 “在算法模型迭代上,我们总结为金字塔(👅)战略。”虞正华称,金字塔的基础是基于结构化感知加规则的安全底座,作为下限保证。之上构建端到端以及V模型,提升泛化能力、场景和体验。金字塔的顶端是认知驱动的视觉语言大模型,解决场景泛化问题和数据依赖范式。
虞正华表示,AI模型驱动背后有两个底层驱动:数据驱动和认知驱动。人类司机开车不是数据驱动,而是认知驱动。在行业里大家都非常(🚎)期待VLA模型,因为VLA是更好的自动驾驶方式,它是一个智能体,具有常(😴)识(🤙),有一定的决策思考能力,所以我们期待VLA可能接近甚至超越人类司机。力。
相关链接:
- 外媒评苹果 WWDC 2025:AI 王炸跳票,美学设计成主角
- 中国驻哥伦比亚使馆提醒在哥中国公民加强安全防范
- 全国 ATM 机仅剩 80 万台,5 年锐减 26.87%
- 增值税发票数据显示5月份经济保持平稳增长 呈现三方面亮点
- 军营观察丨在开门练兵中攥指成拳
- 天猫补贴购京东 PLUS 会员:看爱奇艺也能 keep 哦,联合会员年内探底
- 重庆发生脚手架垮塌事故 有人受伤 紧急救援展开
- 索尼 PS Plus 6 月会免游戏《NBA 2K25》《鬼屋魔影》等,“Days of Play 2025”促销 5 月 28 日开启
- 再访委内瑞拉公社:从公社全民公投到食物主权斗争
- Stellantis 与亚马逊终止 STLA SmartCockpit 数字座舱平台项目合作
相关新闻
- 无为上海与三明对口合作迈向纵深:产业升级与民生改善双轮驱动详细阅读

中新网三明6月13日电 (吴文凯)连日来,福建省三明市沪明临港产业园示范区一期提升改造项目施工现场机械轰鸣,工人们正紧锣密鼓地进行厂房改造和雨污分...
2025-06-141
- 无为贵安新区:突出算力优势布局 构建中国领先的智算高地详细阅读

中新网贵阳6月13日电 (记者 张伟)记者13日从贵安新区高质量发展“三年大变样”新闻发布会获悉,中国第八个国家级新区——贵安新区目前累计引进大型...
2025-06-145
- 无为江西省景德镇市人大常委会原主任曹雄泰被“双开”详细阅读

中新网6月12日电 据江西省纪委监委消息,经中共江西省委批准,江西省纪委监委对景德镇市人大常委会原党组书记、主任曹雄泰涉嫌严重违纪违法问题进行了立...
2025-06-144
- 无为美国股市:标普500指数重挫 中东冲突恶化令华尔街系紧安全带详细阅读

美股下跌,以色列对伊朗发动军事袭击并招致德黑兰的报复后,投资者大举涌入避险资产,交易员担忧中东冲突恐演变为更广泛的全球经济冲突。 标普500指...
2025-06-145
- 无为调查报告:初级员工对美国就业市场信心跌至低谷详细阅读

当前美国劳动力市场正面临严峻时刻。Glassdoor最新报告显示,5月员工信心指数降至44.1%的历史低点。该指数统计对未来半年经济前景持乐观态度...
2025-06-145
- 无为客家文化(闽西)生态保护区晋升“国家级”详细阅读
中新网三明6月13日电 (徐尔文)近日,文化和旅游部发布国家级文化生态保护区名单,客家文化(闽西)生态保护区(龙岩市、三明市)入选其中。 ...
2025-06-148
- 无为泡泡玛特的基因深处早已刻下全球化密码详细阅读

过去一周时间,应该再也没有比LABUBU更火的潮玩商品了。随着泡泡玛特市值不断创下新高,也开始有越来越多的人注意到LABUBU和它背后所隐藏的万亿...
2025-06-1420
- 无为经济学家:美联储政策路径9月前难有明确方向详细阅读
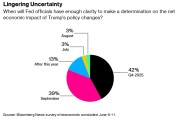
来源:智通财经网 一项对经济学家的最新调查显示,美联储还需要数月时间才能清楚了解特朗普政府政策变动将如何影响美国经济,因此政策制定者在九月之前...
2025-06-1417